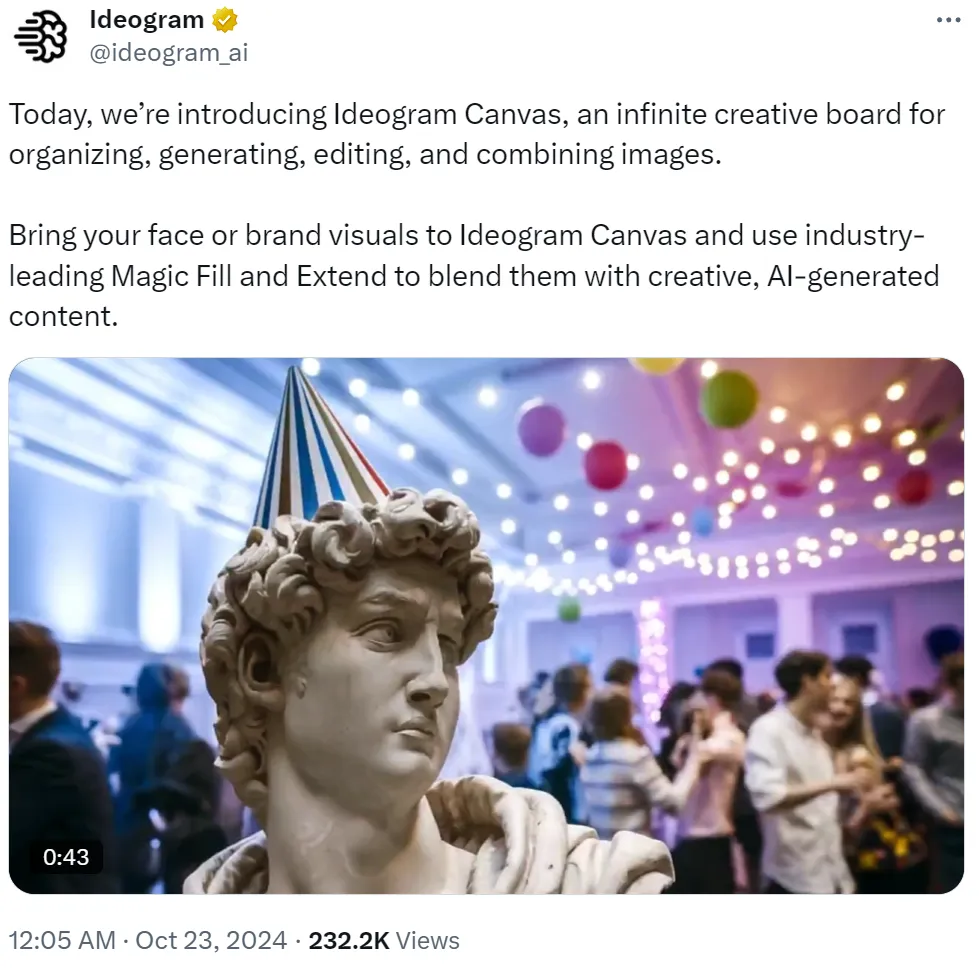
ComfyUI重磅更新:桌面版正式发布,支持win和mac,彻底告别繁琐的安装配置
ComfyUI重磅更新:桌面版正式发布,支持win和mac,彻底告别繁琐的安装配置新手使用 ComfyUI 最大的问题终于被官方解决了!Comfy推出跨平台的 ComfyUI 安装包,你现在可以一键安装 ComfyUI 了。ComfyUI 是一个强大的、基于节点的、用于 Stable Diffusion 的图形用户界面 (GUI)。它允许用户以高度可定制和灵活的方式创建和执行复杂的图像生成工作流程。
来自主题: AI资讯
11005 点击 2024-12-03 11:19